Market value prediction of soccer players
After our first project we dove into machine learning for the first time and learned all the different models for linear regression.
This week I finished my second project in which I put all the new knowledge about linear regression to use.
My objective for this project was to predict the current market value of players in the top five European soccer leagues based on performance and career data. I was able to get insight into which factors have the most impact on the market value to if players are over- or underrated. After scraping data of around 5000 players from the web I came up with 14 features for building my model:
- Age, height, nationality, position, division 1 or 2
- Games, goals, assists, played minutes this season, games for national team
- World Cup or Champions league winner, in team since, expiry of contract, strong foot, total transfer proceeds
Over the course of the project I was able to combine, remove and add additional features to improve the performance of my regression model. After running simple regression models I included ‘games for national team’ and ‘league 1 or 2’ as a feature I ran Random Forest, ExtraTrees, XGBoost and Gradient Boosting models which increased my model’s score to about 80%.
If you look at the importance of each feature it is surprising that games for national team play a huge role in a player’s market value. Age seems to be less important, contrary to my prior expectations.

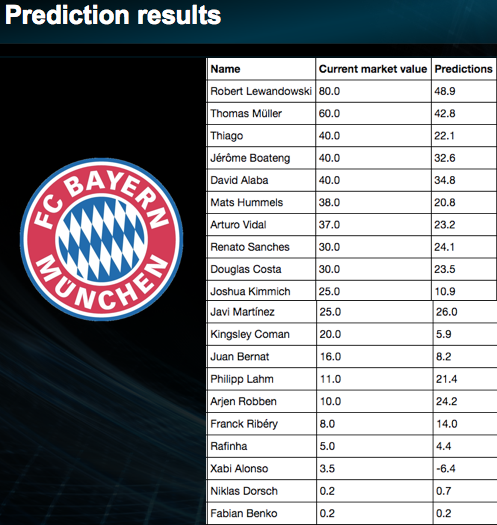
To see how the model performs I predicted the market values for players from FC Bayern Munich. The model seems to be biased when it comes to high valued players which means it predicts a much lower market value. Additionally, it is apparent that a player’s performance isn’t taken into account enough.
Predictions for good players without goals and assists are too low which means that more performance features like in-game stats (pass precision, successful tackles, etc.) have to be included to improve my model. Furthermore, I believe number of injuries, popopularity and performance history play an important role too.
Splitting the data set into players from different positions (offence, midfield, defence) is something I will explore next in order to improve my model.